












初めてパイソンを学習する方のためのサイトです。なるべくシンプルに解説して行きます。Pythonは「読みやすく、書きやすい」文法が特徴のプログラミング言語で、Webアプリ開発、データ分析、AI・機械学習、システム管理など幅広い分野で活用されており、初心者から専門家まで多くの人に人気です。豊富なライブラリやフレームワーク、大規模な開発者コミュニティもPythonの魅力です。
パイソンを勉強しようと思った個人的な理由
9月の終わり、ワードプレス記事の見出し順を上昇順に変えたい件があり、長い記事だったのでエディタ編集も大変でした。ChatGTPに聞いたら「Pythonで簡単にできるよ」と言われ飛びつきました。
Pythonのインストール
以下の手順で、Pythonのインストールを行います。
1.Python公式サイトから、Pythonパッケージをダウンロードします
2.ダウンロードしたパッケージをインストールします。
3.PowerShellでPythonを実行するときに必要となる、スクリプトの実行許可を設定します。
WindowsにPythonをインストールすると、デフォルトのインストール先は以下のようにユーザーディレクトリ内のAppData/Local/Programs/Pythonの中になります。
こちらからWindows用インストーラをダウンロードします。
最新版は3.13.7でした。詳しくはこちらのサイトなどを見てください。
プログラム作成ツール
コマンドプロンプト
Windowsでコマンド(コマンドプロンプト)を起動するには、Windowsキー+Rキーを押して「ファイル名を指定して実行」ダイアログを開き、cmdと入力して「OK」をクリックする方法が最も一般的です。また、Windowsのスタートメニューの検索バーにcmdと入力し改行を押して起動することも可能です。
コマンドプロンプト(ターミナル)で「python ファイル名.py」と入力し実行します。
VSCodeエディタ
VS Codeエディタは、マイクロソフト社がオープンソースで開発しているエディターです。公式Webサイト から無料でダウンロードして利用できます。
VS Codeの特筆すべき特徴が、目的に応じて好きなようにカスタマイズできることです。VS CodeにはHTMLファイルの編集などエディターとしての基本機能が最初から備わっていますが、そこに「拡張機能(Extension)」と呼ばれる機能をインストールして追加できます。
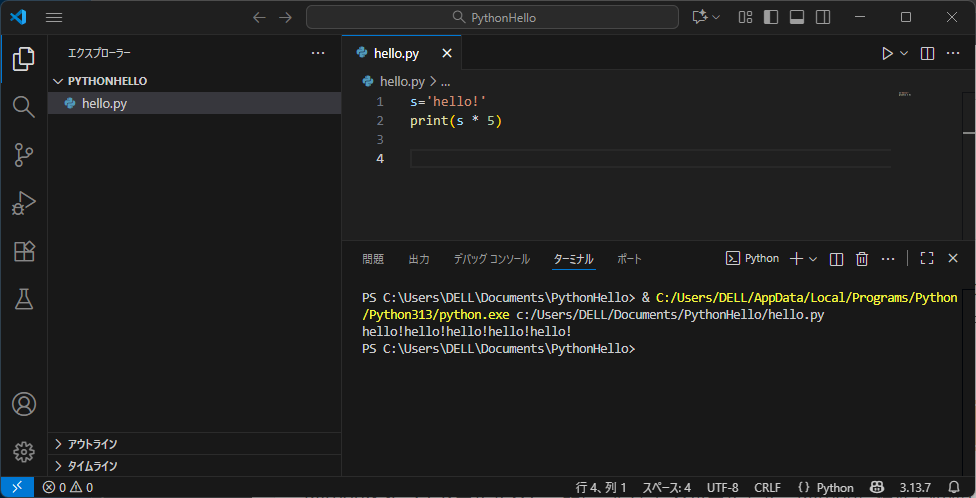
様々な拡張機能が公開されている ので、それらをインストールすれば、PythonやC#など様々な言語を用いたプログラム開発、Jupyterを用いたデータサイエンス、マークダウン記法によるドキュメント作成等、幅広い用途に使えるようになります。
IDLE
Pythonをインストールすると一緒についてくるツールです。Pythonに標準で付属している**統合開発環境(IDE)**です。Pythonのコードを書いたり、実行したり、デバッグしたりできる機能を持ち、特にPythonを学び始めた初心者向けの軽量でシンプルな環境です。
立ち上げ方は:Winボタン→すべてのアプリ→Python3.x→IDLE
Tkinter
Pythonに標準搭載されているGUI(グラフィカルユーザーインターフェース)ライブラリで、ボタンやテキストボックスなどの画面要素を持つGUIアプリケーションを簡単に作成できます。Tcl/TkというGUIツールキットのPython版であり、クロスプラットフォーム対応でWindows、macOS、Linuxなど様々なOSで動作します。
# Tkinterをインポートして使用します。
import tkinter as tk
メモ帳
Windows付属のエディタ「メモ帳」でプログラムを作成し「ファイル名.py」で保存して実行します。
テストするには、編集後に保存(cont+s)して実行(例えばテスクトップに保存されたファイルをダブルクリック)の繰り返しです。これが一番簡単で確実だと思います。
つまり、メモ帳起動→pyファイル編集→cont+s→ダブルクリック→結果見る→ChatGTP先生→編集・修正→cont+s→ダブルクリック・・・の繰り返しです。
プログラムの実行
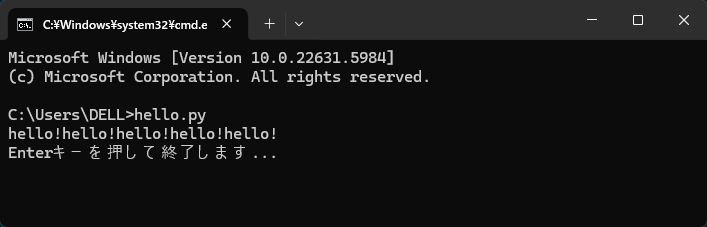
メモ帳で以下のコードを入力しプログラム名と拡張子を、例えば「hello.py」としデスクトップに保存します。これをダブルクリックすればプログラムを手軽に実行することができます。
s='hello!'
print(s * 5)
input("Enterキーを押して終了します...")結果
hello!hello!hello!hello!hello!
Enterキーを押して終了します...※エディタはなるべくUTF-8で保存するメモ帳がいいです。TeraPadなどは保存コードのデフォルトがSift-JISなので変更しないと動作しないこともあります。
※「input(“Enterキーを押して終了します…”)」がないとrunした後に画面が消えてしまうので。
グーグルコラボ
一般的にPythonの実行は、PCのコマンドプロンプトから行いますが、ちょっと面倒ですよね。よりユーザーフレンドリーなグーグルコラボ(Google Colaboratory)を使った環境で実行するととても簡単です。
Google Colaboratory(Google Colab、コラボ)とは、Googleが提供する無料で利用できるオンラインのPython開発環境です。Webブラウザからアクセスし、コードの記述、実行、共有が行えます。インストール不要で、Webブラウザだけで利用できるため、新たに開発環境を構築する必要がありません。
グーグルコラボは、グーグルクロームにログインすれば、以下のサイトから入ることができます。https://colab.research.google.com/
また、グーグルコラボの詳しい使い方に関してはこちらのサイトなど参考にして下さい。
90分、12時間ルール
無料のグーグルコラボでは次のルールがあるので注意しましょう。
- 90分ルール: ユーザーの操作がない場合に適用されるアイドル状態のタイムアウトです。対策は一定時間ごとにノートブックの画面をリロードしたり、セルを操作したりして、アイドル状態と見なされないようにします。
- 12時間ルール: ユーザーが操作を続けていても、連続したセッションの最大時間が12時間を超えると、強制的にセッションが切断されます。対策は12時間経過する前に学習モデルをGoogleドライブ等に保存すること。
.ipynbのファイル形式
Pythonを学習していくと、拡張子が「.ipynb」のサンプルファイルが見かけられます。.ipynbとは、Jupyter Notebookで作成・保存されるファイル形式で、Pythonなどのコード、実行結果、テキスト(説明文)などをすべて1つのファイルにまとめられるのが特徴です。
ファイルの開き方
グーグルコラボを立ち上げると以下の画面が表示されます。
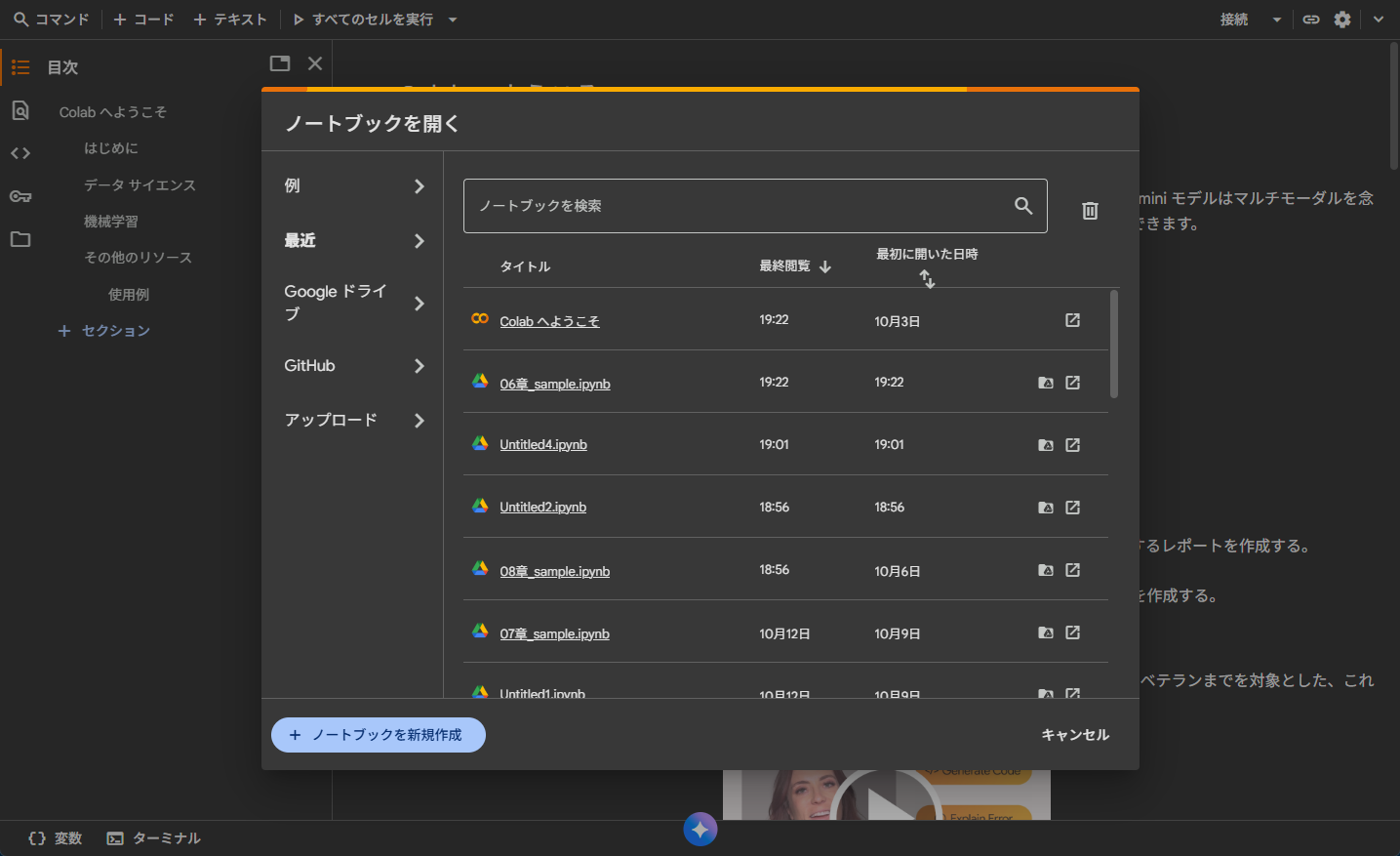
左のアップロードを押し「.ipynb」のサンプルファイルを持ってきます。
通常グーグルコラボはインストールするとGoogleDriveのマイドライブに「Coloab Notebooks」というフォルダが自動的に作られます。そこに拡張子が「.ipynb」のサンプルファイルをコピーして使うと便利です。
Pythonの基礎
コードは小文字で書く?
Pythonでは、変数名や関数名は小文字で書くのが一般的ですが、大文字・小文字は区別されるため、Boolean型 (True, False) や文字列メソッド (upper(), lower()) など、決まった記述の仕方があります。コード全体で小文字と大文字の使い分けには一貫性を持たせることが重要です。
コードの indent
Pythonのコードにおけるインデント(字下げ)とは、コードのブロック(処理のまとまり)を視覚的に区切り、構造を明確にするための空白またはタブのことです。Pythonでは中括弧 {} の代わりにインデントがコードブロックの定義に使われるため、正確なインデントが必須であり、不適切なインデントはエラーを引き起こします。
IndentationError: expected an indented block after 'for' statement on line 1インデントエラー: 1 行目の ‘for’ 文の後にインデントされたブロックが必要です
「for」などの構文の中ではインデント(字下げ)が必要です。
Pythonでは、ブロック(まとまり)をインデントで表す というルールがあります。
つまり、for、if、while、def などの後に書く文は、必ず字下げ(スペースまたはタブ) が必要です。
それ以外のところにインデントがあるとエラーになります、またPythonでは全角スペースはインデントとして認識されず、これもエラーになります。
Print文
Python の print() 文(正確には関数)は、テキスト、数値、変数などの値を画面やファイルに出力するための組み込み関数です。主な使い方は print(出力したい内容) と関数形式で記述し、文字列の表示や変数の値の確認、デバッグなどに使われます。デフォルトでは出力の後に改行が追加されますが、end 引数で改行の有無や末尾に表示する文字を制御し、sep 引数で複数の値を区切る際の文字を指定できます。
演算
>加算や乗算などの四則演算を行ってみましょう。
print(5+3) #足し算
print(5-3) #引き算
print(5*6) #掛け算
print(10/3) #割り算
print(10//3) #割り算小数点以下を切り捨て
print(10%3) #割り算のあまり
print(10**2) #二乗
input("Enterキーを押して終了します...")「結果」
8
2
30
3.3333333333333335
3
1
100
Enterキーを押して終了します...
変数
変数とは、データを入れる箱(入れ物)だと思ってください。変数に値を入れることを代入と呼びます。
Pythonは変数に代入したデータ型によって、自動的にデータ型が決定される言語です。
他の言語だと、整数とかテキストとか型宣言をしますが、Pythonでは不要です。
x = "hello world"
y = 42
print(x)
print(y)
y = 100 # 42から100に上書き
print(y*3.14)データ型
Pythonに限らず、プログラミング言語にはデータの性質を表すデータ型というものがあります。
intは整数型、strは文字列型、floatは浮動小数点型などがあります。
他にリスト型、タプル型、辞書型などがあります。
イテラブル
イテラブルとは、for文などで要素を順次取り出せるオブジェクトのことで、リスト、文字列、`rangeオブジェクトなどが該当します。これらのイテラブルオブジェクトは、データ構造内の要素にアクセスし、繰り返し処理を行うことを可能にします。
各イテラブルオブジェクトの例
- リスト (List):複数のデータを順序付けて格納できるオブジェクトです。
例: [1, 2, 3] や [“apple”, “banana”] - 文字列 (String):文字の並びを表すイテラブルオブジェクトです。各文字を順次取り出せます。
例: “hello” - rangeオブジェクト (range object):数値のシーケンス(範囲)を生成するイテラブルオブジェクト
例: range(5) は 0, 1, 2, 3, 4 という数値を生成します。
関数とライブラリ
Pythonでは関数が特定の処理を行う基本的なコードの部品であり、ライブラリは関連する関数やクラスをまとめたプログラムの集まりです。ライブラリを使うことで、複雑な機能をゼロから作る手間を省き、効率的に開発を進めることができます。ライブラリは通常、import文を使ってプログラムに読み込んでから使用します。
関数(Function)
役割:特定の機能や処理をまとめて名前を付けたものです。例えば、`print()やlen()`のような組み込み関数は、特別な操作なしですぐに利用できます。
使用例:ある計算を繰り返し行う場合、その計算処理を関数として定義しておくと、コードの再利用性が高まります。
ライブラリ(Library)
役割:プログラムで利用できる関数やクラス、モジュール、パッケージなどの集まりを指します。これらをまとめて「ライブラリ」と呼びます。
メリット:数値計算、自然言語処理、データ解析など、自分で実装するのが難しい複雑な処理を、あらかじめ用意されたライブラリの機能を使うことで簡単に実現できます。
If文
if 文は条件分岐の設定です。「もし〇〇なら△△をする」といった処理をしたい時に使います。
具体的には「条件」と「条件が満たされた時の処理」で構成されています。
if文の基本形
if文のもっとも基本となる型は、ifのみの構文です。記述の仕方は以下のようになります。
if 条件式:
条件式が真(true)の場合に実行する処理
この場合、条件式は1つだけになるので、条件式がtrueにならない場合はなにも処理が実行されません。
次のサンプルコードでは、入力された値を参照し、1だった場合のみ「1です」と出力します。
value = int(input('1〜10の数を入力してください'))
if value == 1:
print('1です')if else の形
ifの条件式が偽(false)であった場合の処理を追加するには、if…elseの構文型を使用します。記述の仕方は以下のような形になります。
if 条件式:
条件式が真(true)の場合に実行する処理
else:
条件式が偽(false)の場合に実行する処理
それではサンプルを見てみましょう。次のサンプルコードでは、入力された値を参照し、1だった場合はifの処理が実行され「1です」と出力します。1でなかった場合はelseの処理が実行され「1ではありません」と出力します。
value = int(input('1〜10の数を入力してください'))
if value == 1:
print('1です')
else:
print('1ではありません')
input("Enterキーを押して終了します...")for i in range文
Printを繰り返す
同じことを単純に繰り返します。
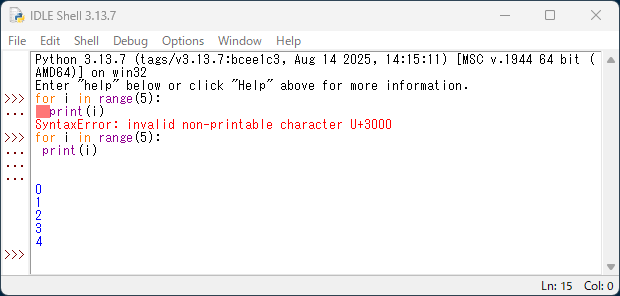
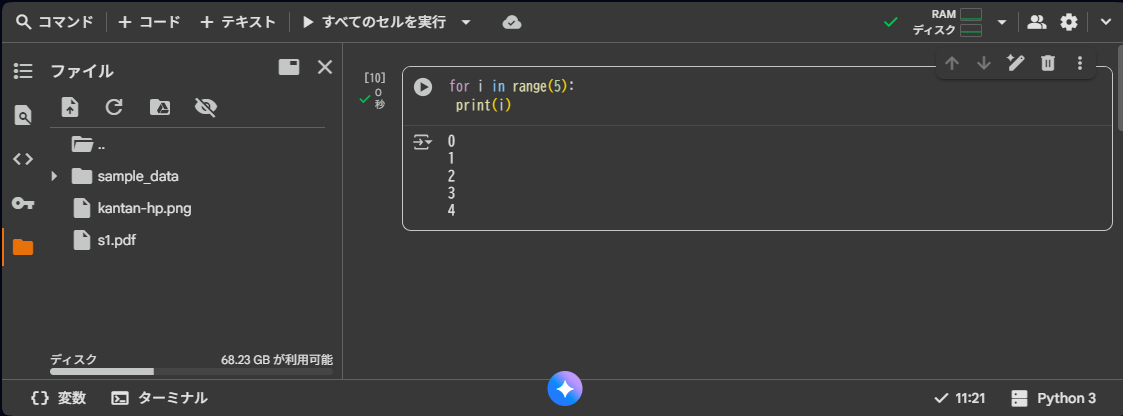
for i in range(5):
print(i)
「結果」0 1 2 3 4※print行にindentがないと、エラーが出るの注意してください!
SyntaxError: expected an indented block after ‘for’ statement on line 1
Forとプリントで繰り返す
s='hello!' #文字列 'hello!' を変数 s に代入しています。
for i in range(1,11): #i が 1 から 10 まで変化します。
print(s * i) #文字列 s を i 回繰り返して表示します。Pythonでは文字列 × 数字で繰り返しができます。
input("Enterキーを押して終了します...")最後のインプット文は結果の画面が消えないようにする待機の役目があります。
hello!
hello!hello!
hello!hello!hello!
hello!hello!hello!hello!
hello!hello!hello!hello!hello!
hello!hello!hello!hello!hello!hello!
hello!hello!hello!hello!hello!hello!hello!
hello!hello!hello!hello!hello!hello!hello!hello!
hello!hello!hello!hello!hello!hello!hello!hello!hello!
hello!hello!hello!hello!hello!hello!hello!hello!hello!hello!
Enterキーを押して終了します...1から10までの合計を計算する
total = 0
for i in range(1, 11):
total += i
print(total)
「結果」55- 初期化
total = 0
→ 変数 total を 0 で初期化します。ここに合計をどんどん足していきます。 - for文のループ
for i in range(1, 11):
→ range(1, 11) は 1から10までの整数 を順番に取り出します。
(Pythonのrangeは「開始値を含み、終了値を含まない」ので、11を指定すると10までになります)つまり、この部分では i が、1, 2, 3, 4, 5, 6, 7, 8, 9, 10と順番に代入されます。 - 合計を更新
total += i → total = total + i の省略形です。
毎回 i の値を total に足し込んでいきます。 - 結果を確認
ループが終わると total には 1から10までの合計 (55) が入っています。
print(total)
出力の値は 55です。
もっと短く書くなら sum 関数を使う
print(sum(range(1, 11))) # 出力: 55for i in range文のinの意味は何か?
for i in range(…) の構文
Pythonのfor文はこういう形をしています:for 変数 in イテラブル:
変数 → ループごとに取り出される値を受け取る
in → 「〜の中から順番に取り出す」という意味
イテラブル → リスト、文字列、range など「順番に取り出せるもの」
つまり、for i in range(1, 11):は
「range(1, 11) の中から値を1つずつ取り出して、変数 i に入れる」という意味です。
なぜ「for range」ではないのか?
rangeは「数列を作る関数」ですが、それだけでは「繰り返し処理をする」にはなりません。
for文は 「inで指定された集まりから1つずつ取り出す」 という決まりで動いています。
たとえば:for x in [10, 20, 30]:
print(x)→ 出力は 10 20 30
ここでは range ではなくリスト [10, 20, 30] を使っていますが、同じように in を使って要素を順に取り出している のがわかります。
inのイメージ
in = 「…の中から」
for i in range(1, 11) = 「range(1, 11) の中から i を順番に取り出す」
だから、for range(…) だけでは 「どこから値を取り出すのか?」がない のでエラーになる。
for文は 「in イテラブル」 という形が必須
in は「その中から1つずつ取り出す」という意味
rangeは単に「数列を生成する関数」であり、in とセットにしてはじめてループ処理に使える
応用プログラム
現在時刻を表示する
JST(日本標準時)を設定して、現在の日本時間を表示します。
# -*- coding: utf-8 -*-
from datetime import datetime, timedelta, timezone
# JST(日本標準時)を設定
JST = timezone(timedelta(hours=9))
# 現在の日本時間を取得
now = datetime.now(JST)
# 曜日を日本語に変換
weekday_ja = {
"Mon": "月",
"Tue": "火",
"Wed": "水",
"Thu": "木",
"Fri": "金",
"Sat": "土",
"Sun": "日"
}[now.strftime("%a")]
# フォーマットして出力
print(now.strftime(f"%Y年%m月%d日({weekday_ja})%H:%M"))
input("Enterキーを押して終了します...")
PDFの操作を自動化
パイソンのライブラリの中から「PyMuPDF」を使ってPDFから文章を抽出したり、ページを加工してみたりします。
最初にPyMuPDFをインストールします。
!pip install PyMuPDF読みとりに使用するテストデータは「ihoujin.pdf」を使います。
import pymupdf
doc = pymupdf.open("ihoujin.pdf")# ihoujin.pdfを読み取り、変数docに入れるpage = doc[0] # 1ページ目の情報を取得
text = page.get_text() # 1ページ目の文字を抽出して変数textに入れる
print(text)「結果」
異邦人(イントロ、レフ3 回) 久保田早紀1978 年
子供たちが 空に向かい 両手を ひろげ
鳥や雲や 夢までも つかもうと している・・・画像処理を自動化
画像加工のライブラリとして「Pillow」があります。画像の読み込み、編集、保存ができます。
読みとりに使用するテスト画像は「kantan-hp.png」(512px*512px)を使います。

最初にPllowをインストールする
!pip install pillow画像を読み込む
from PIL import Image
img = Image.open("kantan-hp.png")画像サイズを取得する
width = img.size[0]
height = img.size[1]
print(f"画像の幅は{width}")
print(f"画像の高さは{height}")
「結果」
画像の幅は512
画像の高さは512画像をリサイズする

resized_width = int(width * 2) # 幅を2倍にしてint型
resized_height = int(height * 0.5) # 高さを0.5倍にしてint型
resized_img = img.resize((resized_width, resized_height))
resized_img.save("resized.png")画像を反時計回りに90度回転する
rotated_img = img.rotate(90)
rotated_img.save("rotated.png")
グレースケールに変換する
grayscale_img = img.convert("L")
grayscale_img.save("grayscale.png")
加工した画像は左サイドバーのファイルに、新しい名前で保存されています。実際に使うには︙からダウンロードして使います。
Webスクレイピングで情報取得
スクレイピングとは、インターネット上に存在するWebサイトから、膨大な量の情報を集めてくることです。ここではテストからHTMLを取得するプログラミングを学習します。
RequestsライブラリでHTMLを取得します。
※コラボではRequestsは、最初からインストールされています。
テスト用のWebサイトからHTMLを取得します(https://k-hp.com/test)
RequestsライブラリでHTMLを取得
import requests# ライブラリを呼び出す
url = "https://k-hp.com/test"# テスト用サイトを定義
response = requests.get(url) # テスト用ページからHTMLを取得
response.encoding = "utf-8" # 文字エンコードをutf-8に指定
print(response.text) # 取得したHTMLを表示Beautiful SoupライブラリでHTMLから情報を取り出す
※コラボではBeautiful Soupは、最初からインストールされています。
Beautiful Soupライブラリでh2タグの情報を取得
from bs4 import BeautifulSoup# bs4はバージョン4の意味
soup = BeautifulSoup(response.text, "html.parser") # Beautiful SoupでHTMLを解析
h2 = soup.find("h2") # h2タグの情報を取り出す
print(h2.text)# 取得したh2タグのテキストを表示
「結果」
君はロックを聴かない全部のh2タグを取得する
h2_tags = soup.find_all(“h2”)# すべての<h2>タグを取得
for i, h2 inenumerate(h2_tags, start=1):# 順に出力
print(f“No.{i}: {h2.text}“)#文字列の中に変数や式を埋め込むための便利な書き方です。
「結果」
No.1: 君はロックを聴かない
No.2: 埃まみれ ドーナツ盤には
No.3: フツフツと鳴り出す青春の音
No.4: 僕の心臓のBGMは
No.5: 君はロックなんか聴かないと思いながら
No.6: 君がロックなんか聴かないこと知ってるけど
No.7: 君はロックなんか聴かないと思いながら
No.8:テキストの並び順を変える
reモジュールは、正規表現を使って文字列のパターンマッチングを行うためのライブラリです。 これを使うことで、文字列の検索、置換、抽出が効率的に行えます。 match():文字列の先頭が正規表現に一致するか確認します。
HTML記事(article.html)の見出し順を上昇順に変えたい
import re#reモジュールを呼び出す
# 記事を保存したファイルとソート先ファイル
INPUT_FILE = "article.html"
OUTPUT_FILE = "article_sorted.html"
# ファイルを読み込む
with open(INPUT_FILE, "r", encoding="utf-8") as f:
content = f.read()
# 見出し<h3>から次の<h3>までを「1話分」として抽出
pattern = re.compile(r'(<h3>第(\d+)話.*?</h3>.*?)(?=<h3>|$)', re.DOTALL)
episodes = pattern.findall(content)
# episodes は [(全体ブロック, "49"), (全体ブロック, "48"), ...] の形になる
# 数字でソート
episodes_sorted = sorted(episodes, key=lambda x: int(x[1]))
# 並び替えたテキストを連結
sorted_content = "\n\n".join([ep[0] for ep in episodes_sorted])
# ファイルに保存
with open(OUTPUT_FILE, "w", encoding="utf-8") as f:
f.write(sorted_content)
print("並べ替え完了! 出力ファイル:", OUTPUT_FILE)
「結果」
並べ替え完了! 出力ファイル: article_sorted.htmlトランプゲーム
ここで作成するのはPC上で楽しめる、トランプゲームの定番「神経衰弱ゲーム」のアプリです。
トランプの画像を用意する
kenneyというサイト(https://kenney.nl/)が配布している無料素材を使います。
Downloadボタンを押すと「kenny_boardgame-pack.zip」というファイルがあります。これを展開すると「ping」フォルダーにある「Card」フォルダー中の画像を利用します。今回使うのはクラブのA~5と、ハートのA~5を使います。
Ping画像を読み込む
今回Pythonの実行は、Google ColaboratoryではなくTkinterを使ってプログラムを作成します。以下はPNG画像を読み込んでCanvasウイジェットに表示するプログラムです。
import tkinter as tk
root = tk.Tk()
root.title('PhotoImage')
root.geometry('250x220')
# カードの裏面の画像ファイルを読み込む
card_back_img = tk.PhotoImage(
file='Cards\cardBack_blue1.png')
canvas_1 = tk.Canvas(
root,
width=240,
height=200)
canvas_1.pack()
canvas_1.create_image(120, 100,
image=card_back_img,
anchor='center')
root.mainloop()
コメント